Defining Sqoop Jobs
This section provides instructions for defining a Sqoop job in TA and descriptions of the various options that can be included in the jobs. The adapter allows for the definition of the job tasks:
-
Code Generation – This task generates Java classes which encapsulate and interpret imported records. The Java definition of a record is instantiated as part of the import process, but can also be performed separately. If Java source is lost, it can be recreated using this task. New versions of a class can be created which use different delimiters between fields or different package name.
-
Export – The export task exports a set of files from HDFS back to an RDBMS. The target table must already exist in the database. The input files are read and parsed into a set of records according to the user-specified delimiters. The default operation is to transform these into a set of INSERT statements that inject the records into the database. In "update mode," Sqoop will generate UPDATE statements that replace existing records in the database.
-
Import – The import tool imports structured data from an RDBMS to HDFS. Each row from a table is represented as a separate record in HDFS. Records can be stored as text files (one record per line), or in binary representation such as Avro or SequenceFiles.
-
Merge – The merge tool allows you to combine two datasets where entries in one dataset will overwrite entries of an older dataset. For example, an incremental import run in last-modified mode will generate multiple datasets in HDFS where successively newer data appears in each dataset. The merge tool will "flatten" two datasets into one, taking the newest available records for each primary key.
This can be used with SequenceFile-, Avro-, and text-based incremental imports. The file types of the newer and older datasets must be the same. The merge tool is typically run after an incremental import with the date-last-modified mode.
To define a Sqoop job:
-
Click Definitions > Jobs to display the Jobs pane.
-
Right-click Jobs and choose Add Job > Sqoop Job from the context menu.
The Sqoop Job Definition dialog appears.
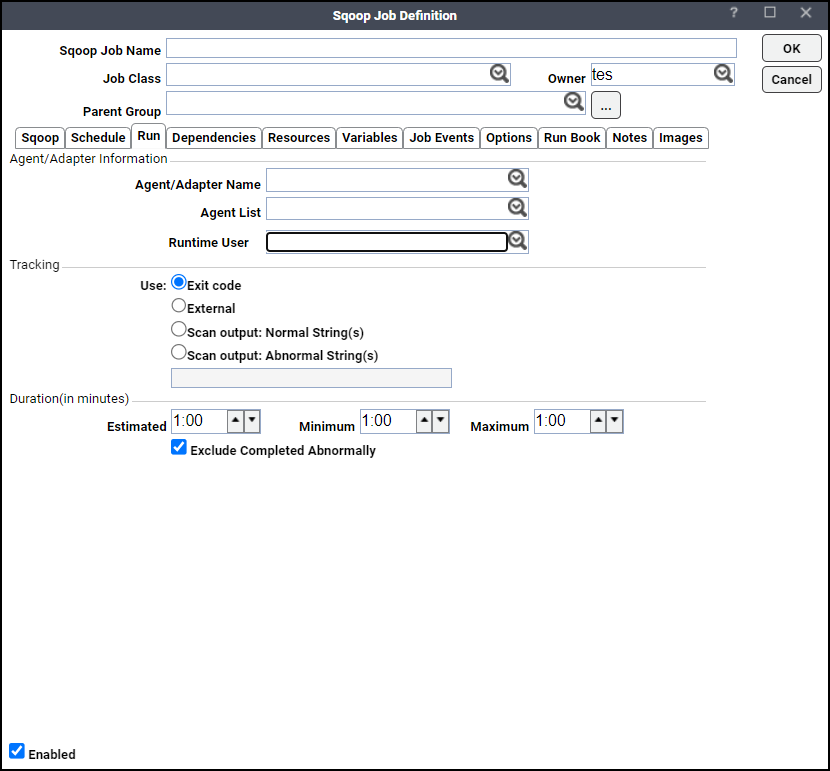
The Run tab is selected by default. You must first specify a name for the job, the adapter connection that will be used for the job and a valid runtime user who has the appropriate Sqoop authority for the report being scheduled.
-
Specify the information to describe the job:
-
Job Name – Enter a name that describes the job.
-
Job Class – If you want to assign a defined job class to this job, choose it from the drop-down list. This field is optional.
-
Owner – Choose the Sqoop owner of the selected job. The user must have the appropriate Sqoop authority for the operation.
-
Parent Group – If this job exists under a parent group, choose the name of the parent group from the drop-down list. All properties in the Agent Information section are inherited from its parent job group.
-
-
Specify this connection information in the Agent/Adapter Information section:
-
Agent/Adapter Name – Choose the adapter connection to be used for this job from the drop-down list.
OR
Agent List Name – Click a list for broadcasting the job to multiple servers.
-
Runtime User – Choose a valid runtime user with the appropriate Sqoop authority for the job from the drop-down list.
-
-
Specify the appropriate Tracking and Duration information for the job. Refer to the Tidal Automation User Guide for information on these options.
-
Click the Sqoop tab, to specify the job configuration.
-
From the Sqoop Task list, choose a job task type and enter the task details as described in these sections:
-
Click OK to save the job.