Defining a Connection
Create one or more Hadoop MapReduce connections before TA can run your adapter jobs. License these connections before TA can use them. A connection is created using the Connection Definition dialog.
To define a connection:
-
Navigate to Administration > Connections from the Navigation pane to display the Connections pane.
-
Right-click Connections and choose Add Connection > MapReduce Adapter from the context menu. The MapReduce Adapter Connection Definition dialog appears.
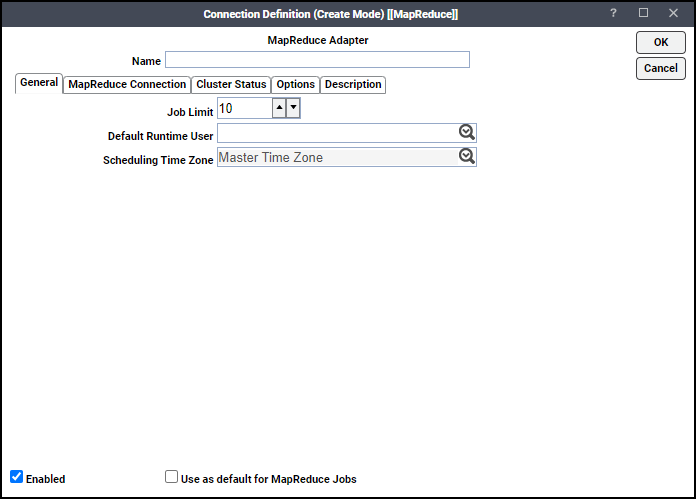
-
Enter a name for the new connection in the Name field.
-
Enter the maximum number of concurrent active processes in the Job Limit field that TA submits to the Hadoop server at one time.
Note: From the Default Runtime User drop-down list, you have the option to click the name of a default user for adapter jobs. The runtime user is auto-selected when defining adapter jobs.
Only authorized users that have been defined with MapReduce passwords display in this list. The selected user is automatically supplied as the default runtime user in a new adapter job definition. -
Click MapReduce Connection. The tab contents are different depending on whether the connection is for Hadoop 1 or Hadoop 2 as shown in the two examples here.
MapReduce connection definition for Hadoop 1:

MapReduce connection definition for MapR Hadoop 2:

-
Enter the input fields depending on whether the connection is for Hadoop 1 or Hadoop 2. These fields are required:
-
Distribution Type – Specify the Hadoop distribution that you are using.
-
Resource Manager – Enter YARN for Hadoop 2 and Job Tracker for Hadoop 1.
-
Client Jar Directory – Enter the path to the directory where all the Hadoop client libraries reside.
Note: The Client Jar Directory input field needs to point to a separate directory path for each additional connection. This is because the Hadoop client jar files retain state information and using the same directory for multiple connections can corrupt other connections
-
YARN (Hadoop 2 only) – Enter the hostname and port at which YARN is running.
-
Resource XML (Hadoop 2 only) – Get the mapred-site.xml from your Hadoop installation, copy the file to the TA Master, and provide the path here.
If you are using MapR, provide the path of the core-site.xml file as well after suitably editing the file following instructions in MapR Client Software Requirements.
Ensure that the mapred-site.xml file defines the properties:
mapreduce.application.classpath
yarn.application.classpath
mapreduce.jobhistory.address
mapreduce.jobhistory.intermediate-done-dir
yarn.app.mapreduce.am.staging-dir
yarn.resourcemanager.scheduler.address mapreduce.app-submission.cross-platform
When TA Master is running on Windows mapreduce.app-submission.cross-platform should be set to true.
Note: If you are using Kerberos authentication, make sure to import the files to the TA Master and supply as comma-separated input to the Resource XML field: mapred-site.xml, hdfs-site.xml, core-site.xml, yarn-site.xml. Make sure that any environment variables used in these files are resolved to their value (for example $PWD is resolved to an absolute directory path).
-
Job Tracker (Hadoop 1 only) – Enter the location of your Job Tracker.
-
Name Node – Enter the URI of the Name node.
Note: For MapR, Job Tracker and Name Node must be set to "maprfs:///".
-
-
Navigate tothe Hadoop User list, click the associated Runtime User for MapReduce to be used to monitor connection health and job execution.
This is a persistent user connection that is only used for administration and monitoring and for jobs with a matching runtime user. Jobs with a different runtime user specified will create additional temporary connections.
Note: It is recommended that the connection's Hadoop user be a Hadoop Super User and is a requirement to display Distributed File System statistics in the Cluster Status tab.
-
(Optional) Click Test to verify connectivity.
-
(Optional) Specify the Kerberos information if the Hadoop cluster is secured by Kerberos.
-
Check the Kerberos Authentication checkbox and specify the Job Tracker (Hadoop 1) or Mapred principle (Hadoop 2), HDFS Principal, and YARN principal (Hadoop 2 only).
The Kerberos User Principal and Kerberos Key Tab file associated with the Hadoop user is configured during Step 10.
A Kerberos principal is used in a Kerberos-secured system to represent a unique identity. Kerberos assigns tickets to Kerberos principals to enable them to access Kerberos-secured Hadoop services. For Hadoop, the principals should be in this format:
username/fully.qualified.domain.name@YOUR-REALM.COM
where username refers to the username of an existing Unix account, such as hdfs or mapred.
Note: Kerberos is supported starting with MapR version 5.
Kerberos authentication is optional, but if the Hadoop cluster is secured by Kerberos, Kerberos information must be configured.
Service.props
MapReduce User Definition
MapReduce Connection Definition
-
Click Cluster Status to display current cluster’s status in real time. This is for the display of Distributed File System (DFS) info and requires a Hadoop Super User.

You can double-click Task Trackers and Data Nodes to view the additional dialogs.
-
Click Options to specify Global Job Parameters that are applicable to all jobs using the connection. If the job definition specifies the same job parameters, the values defined in the job definition will override the corresponding connection values. The Configuration Parameters are general connection parameter options.

This tab contains these elements:
-
Polling Interval (in seconds) – Specifies the connection polling.
-
Connection Poll – Select how often the connections should be polled for status.
Note: To configure Connection polling, include CONNINFOPOLL in the Configuration Parameters section. This indicates how often the connection should be polled for system status and job load information. If not explicitly specified, the adapter uses a default of 10 seconds.
-
Global Job Parameters – Specify additional job parameters. If specified, these options are applied to all MapReduce jobs running on this connection.
The supported configuration parameters includes:
-
CONNECT_TIMEOUT – the timeout interval in seconds (default 20) in which a failed connection will timeout, avoiding further connection retries.
-
MAX_OUTPUTFILE_SIZE – in kbytes (default 1024 kbytes). This option is used to determine whether or not MapReduce output should be retrieved during output collection. If the output file exceeds this configured limit, output collection for this file will be avoided.
-
-
Click Add to add a parameter.
-
Click OK to save the new MapReduce connection. The configured connection displays in the Connections pane.
Verifying Connection Status
The status light next to the connection indicates whether the TA Master is connected to the MapReduce server. If the light is green, the MapReduce server is connected.
A red light indicates that the Master cannot connect to the MapReduce server. MapReduce jobs will not be submitted without a connection to the MapReduce server. You can only define jobs from the Client if the connection light is green.
If the light is red, you can test the connection to determine the problem. Right-click the connection and click Test. A message is shown on the Test MapReduce Connection dialog describing the problem. Or go to Operator > Logs to look for error messages associated with this connection.